Getting Started
The Cochl.Sense Cloud API analyzes pre-recorded audio files for sound events, speech, and high-level scene insights. It accepts MP3, WAV, FLAC, and OGG inputs—start analyzing your audio without any conversion step.
1. Set up Python environment
Cochl.Sense Cloud API can be easily integrated into any Python application using the Cochl library. The library supports Python versions 3.10 or higher. Please make sure you’re using a compatible version of Python. First, create a Python virtual environment.
python3 -m venv venv
. venv/bin/activate
pip install --upgrade pip
pip install --upgrade cochl
git clone https://github.com/cochlearai/cochl-sense-py.git
cd cochl-sense-py/samples
python3 -m venv venv
. venv/bin/activate
pip install --upgrade pip
pip install --upgrade cochl
git clone https://github.com/cochlearai/cochl-sense-py.git
cd cochl-sense-py/samples
python -m venv venv
.\venv\Scripts\activate
pip install --upgrade pip
pip install --upgrade cochl
git clone https://github.com/cochlearai/cochl-sense-py.git
cd cochl-sense-py/samples
2. Get Your Project Key
To use the solution, create a project in the Dashboard and copy the project key. For details, see the guide here.
Project keys don’t expire. If you need to rotate one, regenerate it from the project’s Settings tab on the Dashboard — the old key stops working immediately and the new key takes effect right away.
3. Run the Example
- File samples can also be found here.
- Supported file formats for the Cochl.Sense Cloud API: MP3, WAV, FLAC, and OGG.
- A single upload is capped at 1 hour of audio. There is no concurrent-request limit.
If a file is not in a supported format, it must be manually converted. More details can be found here.
This simple setup is enough to upload your file and run analyses. Using the IntegratedApi, you can run Sound Event Detection, Speech Analysis, and Audio Insights in a single upload. Please input your retrieved API project key into “YOUR_API_PROJECT_KEY”.
from cochl.sense import IntegratedApi, IntegratedApiOptions
api = IntegratedApi('YOUR_API_PROJECT_KEY')
job = api.analyze_file(
'your_file.wav',
IntegratedApiOptions(
sound_event_detection=True,
speech_analysis=True,
audio_insights=True,
),
)
result = api.get_completed_result(job['job_id'])
# result['sound_event_detection'] — SED chunks
# result['speech_analysis'] — Speech Analysis segments
# result['audio_insights'] — Audio Insights summary
4. Valid Service Combinations
audio_insights is built on top of the other two analyses, so it can’t run on its own — enable it only together with both sound_event_detection and speech_analysis. At least one service must be enabled. Invalid combinations will return a 400 error.
sound_event_detection | speech_analysis | audio_insights | Result |
|---|---|---|---|
| ✅ | ❌ | ❌ | OK — SED only |
| ❌ | ✅ | ❌ | OK — Speech Analysis only |
| ✅ | ✅ | ❌ | OK — SED + Speech Analysis |
| ✅ | ✅ | ✅ | OK — full stack (Dashboard default) |
| ❌ | ❌ | ❌ | 400 — no services selected |
| ❌ | ❌ | ✅ | 400 — audio_insights requires both SED and Speech Analysis |
| ✅ | ❌ | ✅ | 400 — audio_insights requires speech_analysis |
| ❌ | ✅ | ✅ | 400 — audio_insights requires sound_event_detection |
Sample response
Running the all-three example above on a 30-second interview clip produces a result like:
{
"sound_event_detection": {
"status": "success",
"results": [
{
"start_time": "00:00.00",
"end_time": "00:01.00",
"start_time_sec": 0.0,
"end_time_sec": 1.0,
"classes": [
{ "class": "Speech", "confidence": 0.94 },
{ "class": "Male_speech", "confidence": 0.81 }
]
},
{
"start_time": "00:01.00",
"end_time": "00:02.00",
"start_time_sec": 1.0,
"end_time_sec": 2.0,
"classes": [
{ "class": "Male_speech", "confidence": 0.88 }
]
}
]
},
"speech_analysis": {
"status": "success",
"results": [
{
"speaker": "SPEAKER_00",
"speaker_name": null,
"speaker_score": null,
"transcript": "So, growing up, your father had a really strong influence on you.",
"start_time": "00:00.00",
"end_time": "00:04.32",
"start_time_sec": 0.0,
"end_time_sec": 4.32
},
{
"speaker": "SPEAKER_01",
"speaker_name": "Christian_Bale",
"speaker_score": 0.41,
"transcript": "Yeah, he taught me to never settle for the obvious choice.",
"start_time": "00:04.60",
"end_time": "00:08.91",
"start_time_sec": 4.6,
"end_time_sec": 8.91
}
]
},
"audio_insights": {
"status": "success",
"result": {
"contains_speech": true,
"detected_language": "English",
"primary_sound_environment": "Speech-dominated, likely an interview",
"situation_summary": "The audio captures an interview where Christian Bale reflects on his father's influence and his approach to acting.",
"notable_events": ["Male_speech", "Speech"],
"speech_content_summary": "Bale credits his father for teaching him to look past obvious choices when picking roles.",
"keywords": ["Christian Bale", "father", "upbringing", "acting"]
}
}
}
A few things to notice:
sound_event_detection.results[]has one chunk per inference window (~1 s). Many chunks for a 30 s file.speech_analysis.results[]has one segment per speaker turn — variable length.audio_insights.resultis one object for the whole file (no time chunks).speaker_name: "Christian_Bale"appears because a profile with that name was registered via Custom Sound: Speaker Profile, andspeaker_scoreis the similarity against that profile. Unmatched turns leave both asnulland you fall back to the diarization label (SPEAKER_00,SPEAKER_01, …).
Time format
Every result item carries both a numeric start_time_sec / end_time_sec (float seconds) and a human-readable start_time / end_time string. The string format adapts to file length:
- Under 1 hour —
MM:SS.SS(e.g."05:32.10"). - 1 hour or longer —
HH:MM:SS.SS(e.g."01:01:58.52").
Always parse start_time_sec / end_time_sec for math; the string fields are for display only.
IntegratedApi returns a different (Integration API) result shape than Client. See the Field Name Cheat Sheet in Sound Event Detection before migrating.
5. What’s next
- Sound Event Detection—detection details, both client shapes
- Speech Analysis—transcribe speech and identify registered speakers
- Audio Insights—single-paragraph scene summary
- REST API Reference—HTTP interface for non-Python clients
6. Usage & Pricing
The Cochl.Sense Cloud API is billed per minute of analyzed audio, charged separately by service.
| Service | Price |
|---|---|
| Sound Event Detection | $0.012 per minute |
| Speech Analysis | Free (introductory) |
| Audio Insights | Free (introductory) |
Speech Analysis and Audio Insights are newer features, currently offered free of charge while we broaden the experience — pricing may be introduced later. When you combine services in a single request, each is billed independently; today only Sound Event Detection incurs a charge.
Note that Audio Insights can’t run on its own — it requires both Sound Event Detection and Speech Analysis (see Valid Service Combinations). So even though Audio Insights is free, using it always enables Sound Event Detection, which means you’re effectively paying the Sound Event Detection per-minute rate.
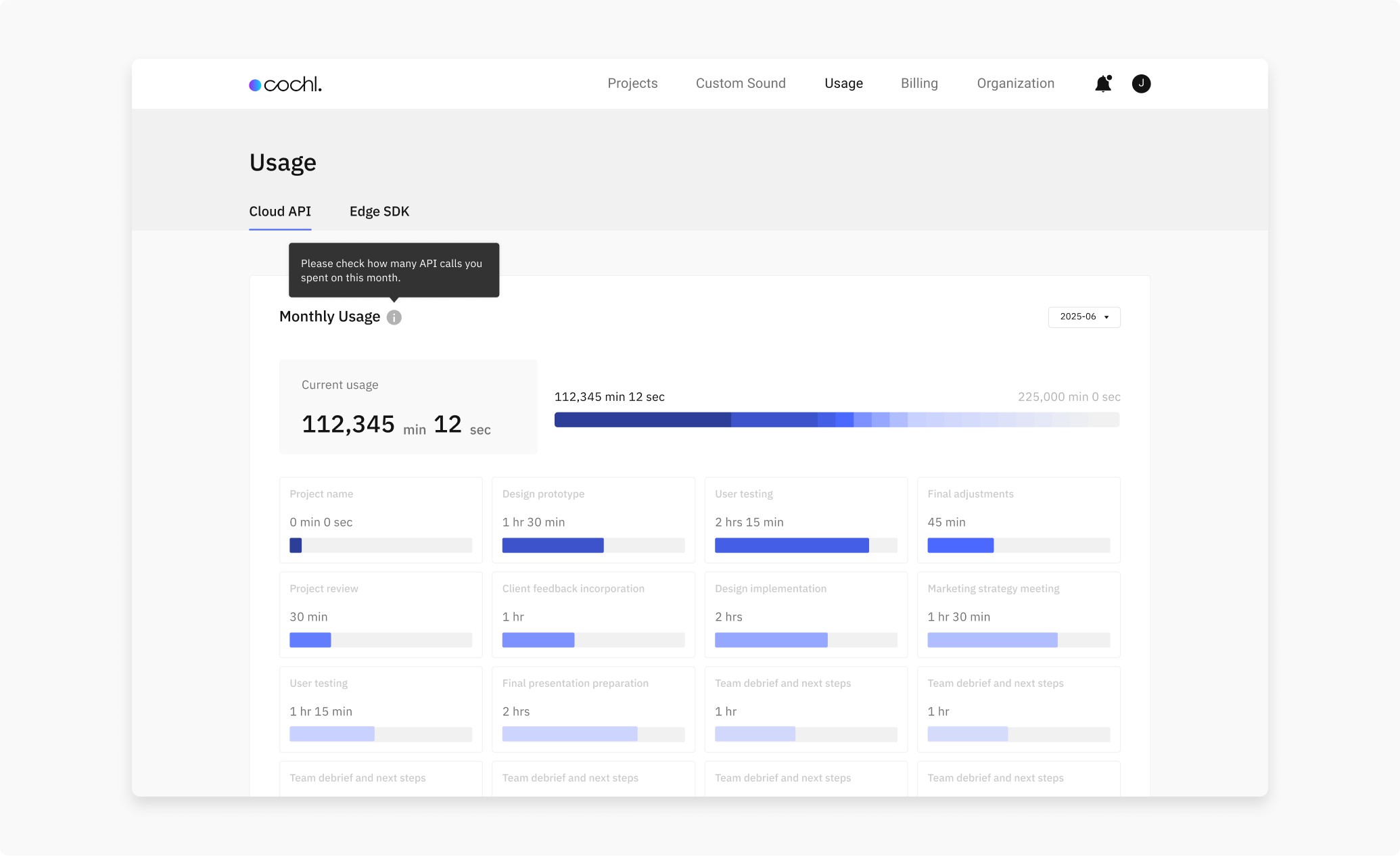
You can review your usage on the Cochl.Sense Dashboard.
7. Additional Notes
(1) Convert to supported file formats (MP3, WAV, FLAC, OGG)
Pydub is an easy way to convert audio files into one of the supported formats.
First, install Pydub by following the instructions in this link. Then, write a Python script to convert your file, as shown below.
from pydub import AudioSegment
audio = AudioSegment.from_file("sample.mp4", "mp4")
audio.export("sample.mp3", format="mp3")
For more details of Pydub, please refer to this link.