Sound Event Detection
Sound Event Detection (SED) is the on-device sound recognition capability of the Cochl.Sense Edge SDK. It runs entirely on the edge—no cloud round-trip, no audio leaves the device—and produces the same tag-and-probability output as the Cloud API equivalent.
This page covers SED behavior in the Edge SDK. For installation and your first prediction, start with Getting Started and Samples.
1. How it works
The SDK ships a TensorFlow Lite model that runs on CPU by default and can be delegated to GPU/NPU on supported devices. It processes audio in fixed-size windows (the “window size”) with a configurable stride (the “hop size”) and emits a result per window.
Each result includes the predicted tags and their probabilities, plus the time interval of the window. Adjacent windows can be merged into a single event using Result Summary.
2. Choose your tags at project creation
Unlike the Cloud API—which detects every official tag by default—an Edge SDK project ships with only the tags you select when creating the project on the Dashboard. The on-device model is built for that exact tag subset, which keeps the model lean and inference fast on edge hardware.
What this means in practice:
- Pick the tags you actually need at project creation. Browse the catalog on the Sound Tags page first.
- To add or remove tags later, edit the tag list on the project page in the Dashboard. The next time your app initializes the SDK, it downloads the updated model.
- If the sound you care about isn’t covered by built-in tags, train a custom one via Custom Sound: Sound Events. Training runs on Cochl’s infrastructure; once it finishes the new tag appears in the Custom Sound sub-tab of the tag picker and the SDK downloads the updated model on next initialization.
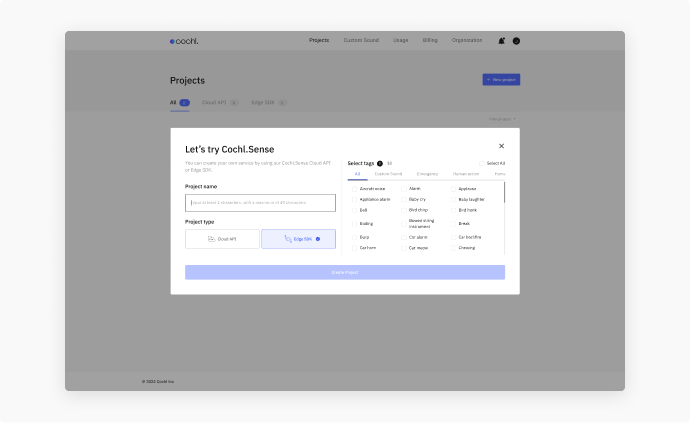
The catalog covers 100+ tags across eight categories — a taste of what’s in each:
You can inspect the tags currently active on the device via getSelectedTags() (Java).
3. Two modes: file vs. stream
| Mode | Source | Use case |
|---|---|---|
| File mode | wav / mp3 on disk | Batch processing, testing, post-hoc analysis |
| Stream mode | Live audio buffer (mic, network) | Real-time monitoring, alerts |
Both modes return the same result schema:
{
"tags": [
{ "name": "Siren", "probability": 0.81 }
],
"start_time": 3.0,
"end_time": 4.0,
"prediction_time": 24.5
}
prediction_time is the SDK’s inference latency for that window, in milliseconds—useful for confirming you’re meeting your latency budget on the target device. For the full field-by-field spec and per-language code samples, see Samples.
4. Tune detection behavior
The SDK reads config.json on initialization. Three knobs control SED behavior:
- Sensitivity control—global and per-tag, range
-2to2. - Result summary—merges adjacent same-tag windows. (In stream mode, only enable/disable is honored; the merge happens after each prediction.)
- Audio preprocessor—optional
audio_activity_detection(skip silent windows) andautomatic_gain_control(normalize quiet/loud input).
Full schema and field-by-field reference: Advanced Configurations.
5. Performance
SED model accuracy and latency vary by device. Per-platform measurements are in Benchmark.
Current Edge SDK model has improved Average Precision (AP) by approximately 17% over the previous release, with the biggest gains on small target sounds and noisy environments. See Release Notes for the version history.
6. Limitations
- Sample rate — 22,050 Hz or higher is recommended. Lower rates (e.g. 16 kHz) still work — the SDK upsamples them internally — but accuracy is best when the input is already at or above 22,050 Hz. Higher rates are auto-downsampled.
- File length in file mode must be ≥ the model window size (call
getWindowSize()to check). - The SDK requires an outbound network connection on first run to download the model and verify license. After initial setup, prediction is fully offline; license verification re-runs periodically.